Restate 1.2: a distributed durable execution engine, built from first principles
Ahmed Farghal, Till Rohrmann, Nik Nasr, Giselle van Dongen, Jack Kleeman, Francesco Guardiani, Igal Shilman, Muhamad Awad, Pavel Tcholakov, Stephan Ewen
Restate lets you write mission-critical applications, like payment workflows, user management, and AI agents, without worrying about resiliency. With Restate 1.2, you can now run these applications at scale with highly-available Restate clusters that tolerate node failures while keeping your applications responsive, resilient, and consistent. Restate is designed to run well wherever you want it to: on cloud, on-prem, across AZs, and even across regions. Restate now also includes a graphical UI to give you an intuitive way to introspect and debug your applications.
Restate is open, free, and available at GitHub or at the Restate website.
The simplest way to write resilient applications
It’s still too hard to write applications that are fully resilient. Wouldn't it be great if you could stop worrying about all possible failure scenarios and race conditions in your applications such as charging customers twice, users withdrawing more cash than they have, and selling a single ticket multiple times? Application code is flooded with retry, recovery, and coordination logic across message queues, key-value stores, workflows, and cron jobs. This turns our applications into distributed systems that are hard to reason about and hard to debug.
Restate solves this by capturing all application activity—RPC calls, timers, promises, API calls—into a single, reliable log. In case of failures, Restate retries the execution and recovers the process and all previous state. Restate automatically mitigates against a large class of infrastructure failures, race conditions, timeouts, and other inconsistencies.
This concept is often called Durable Execution. Restate is a Durable Execution engine with some unique characteristics:
- Simple, flexible programming model: an intuitive microservice-style API to express your business logic purely in code. No need to mash your business logic into YAML workflow definitions or intertwine it with event-based programming models, just to get the resiliency you want.
- Easy to deploy and operate: Restate is a single binary - no need to deploy databases, queues or extra dependencies to make it work. Together with the Restate CLI for debugging and inspection, this makes developing with Restate a nice experience.
- Smart integration with serverless platforms by suspending waiting functions.
- Detailed observability into how your requests are executed across your services without complex tools and setups
Our flavour of durable execution is the perfect match for stateful asynchronous programs, like AI Agents. Anthropic recently discussed ways to implement AI Agents, like chaining LLM API calls, dynamic/flexible routing, parallelization, and orchestration. Restate excels at all of these by making them easy to implement and fully resilient by default.
Restate can help power any application requiring resiliency and consistency, such as payments, inventory management, managing user signups and subscriptions, order processing, but also technical patterns like sagas, distributed transactions, task fan-out/fan-in, and async task scheduling.
Since we released the first version of Restate, many developers have fallen in love:
- “We built a quite complex application with Restate earlier this month, and I can say, after you build a distributed state machine with it you can’t go back to DIY”. - Aris Koliopoulos, Rated labs
- “Moving to Restate has been a game-changer for Rhize. The fine balance of simple elegance and power is brilliant.” - Rhize Manufacturing
- "Restate makes our code simpler, more reliable, and easier to test— it’s night and day compared to step functions. You’ll find yourself reaching for it again and again" - Andy Smith, Uniswap
- “It is the first system in a long time that got me excited” - Sr. Engineer, major financial services company
As users get the appetite for Restate and want to move more mission-critical workloads to it, the most prominent request we got was highly-available distributed deployments.
Distributed deployments for mission-critical workloads
From day one, Restate was designed as a highly-available system that is easy and flexible to operate, scales with your business needs, runs efficiently on cloud and on-prem, while retaining the nice aspects of the single-node version, including low latencies, and the great developer experience of a single binary.
After months of hard work, it’s finally here:
High-availability and fast fail-overs
You can now scale out your Restate Servers and run them in a highly-available, distributed setup. Restate runs active-active deployments, with data getting copied instantly for fast, consistent fail-over.
Have a look at how our counter service remains correct throughout node failures, or run the demo yourself:
Simple to deploy, operate and scale
Restate runs as a single binary. You deploy the process across nodes, AZs, or regions, and it's ready to go. Nodes can periodically snapshot to a persistent volume or object store, simplifying operations in the cloud.
The single binary runs a few different roles: log servers, workers, control plane. You can fine-tune which roles run on which nodes and scale them independently. This modular approach lets you add more resources where needed - for example, more computing power or storage capacity.
Have a look at how we start with a single-node cluster and scale out by spinning up extra nodes and adjusting the replication settings. Restate’s segmented log design allows reconfiguration on the fly, making scaling up a matter of clicking a button.
Workflow semantics everywhere without sacrificing latency
Durable Execution gives workflow-like semantics (retries and recovery of progress) wherever you want it. Workflow orchestrators often have the connotation of being slow and not apt for latency-sensitive tasks, with workflow submission times of a second or more. With Restate this changes.
Restate’s design focuses on keeping latency low, so you can get workflow semantics anywhere, without sacrificing performance. This lets you use Restate for latency-sensitive tasks, like instant payments, interactive AI, and event processing from Kafka.
Here are some latency measurements for a 3-way replicated cluster of 3 nodes under low and high load:
| load | p50 | p75 | p90 | p99 | |
|---|---|---|---|---|---|
| 3-step workflow | 549 rps (low) | 15ms | 30ms | 42ms | 69ms |
| 9-step workflow | 303 rps (low) | 31ms | 45ms | 57ms | 93ms |
| 1-step workflow | 23 131 rps (high) | 16ms | 20ms | 25ms | 40ms |
| 3-step workflow | 16 844 rps (high) | 58ms | 67ms | 76ms | 98ms |
| 9-step workflow | 8 571 rps (high) | 116ms | 126ms | 138ms | 163ms |
At low load, the 3-step workflow had a median latency of 15ms. Load can be pushed to 17 000 requests per second (84 000 actions per second) with a p90 latency of 76ms.
Our next blog post will describe the design decisions we made to improve latency. You can also run this benchmark yourself on your own workloads.
Mature operational tooling
Restate already included a CLI to inspect services and invocations, which is a big help for application developers. To provide the same experience for operators, Restate 1.2 includes a new cluster administration tool. With restatectl, you can check the status of your cluster, view the partitioning layout, change the configuration of your cluster, and take snapshots.
We used restatectl pretty heavily in the previous demos. Here is an example of how you can use it to check the status of your cluster:

Install restatectl and try it yourself.
Peek under the hood
Hold up, sub-50ms workflows, fast fail-overs, fine-grained scaling,… How is all of that possible?
Restate is built from the ground up as a database for Durable Execution, with a distributed log and consensus algorithm at its core. The design is based on Virtual Consensus and ideas from LogDevice, and uses strong consensus in the control plane and relaxed requirements on the data plane, to improve efficiency and flexibility.
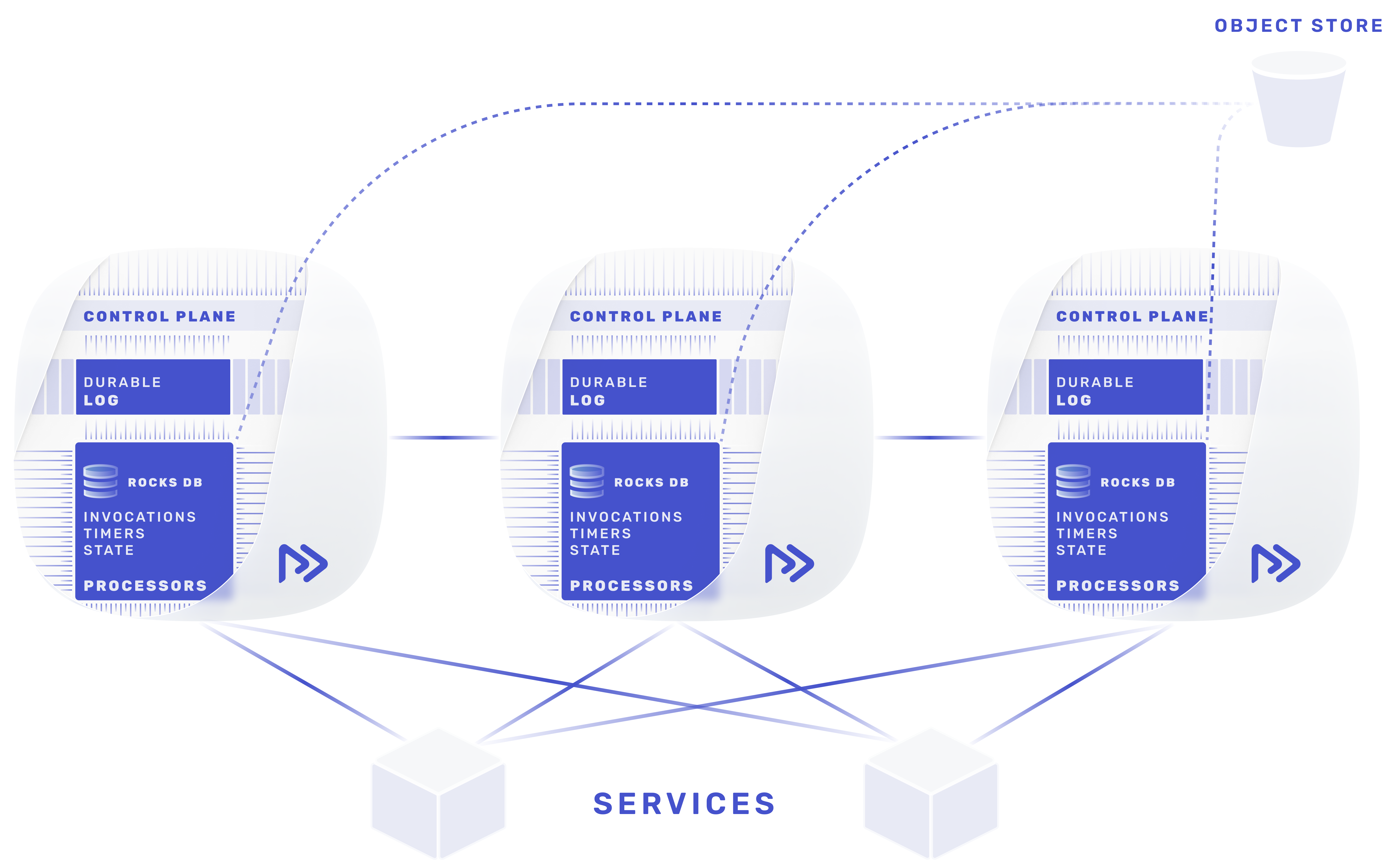
The system has a tiered architecture:
- A log for primary durability and fast appends
- Embedded RocksDB tables for storing invocations, state and timers
- Object store for persisting snapshots of the RocksDB tables
This tiered approach has several benefits (similar as to Kafka’s tiered architecture). Restate only needs to guard a few minutes worth of data, while most of it is stored in snapshots on object store. By keeping less data locally coupled to Restate Servers, clusters can scale up, recover, and reconfigure more quickly. It is also more cost-effective since object storage is less expensive.
If you look at Restate’s architecture, you might wonder why we didn’t just build this on top of an existing database or queue? We believe you can’t.
We built our own implementation of a distributed replicated log, because we didn't find any of the existing logs suitable in terms of latency (single roundtrip, quorum replication with external consensus), durability (active-active with flexible quorums), and flexibility (segmented log that can be dynamically reconfigured).
The set of properties we need isn't found in many databases, let alone a full durable execution stack. But it is a killer experience when it exists, so we built it.
There is so much to say about the design of Restate, so in the coming days, we will publish a deep dive blog post on the internals. For now, you can satisfy your curiosity with the earlier blog post we wrote on Distributed Restate.
Graphical UI: Insights beyond your usual queue
The Restate 1.2 release contains another big feature. Restate has always featured a great CLI to introspect state, workflows, and invocations. We are now adding a graphical UI as an easy and intuitive way to manage, navigate, and debug your Restate applications.
When the industry moved to microservice architectures, we lost a lot of simplicity and flexibility in observing, monitoring and debugging applications. The sheer number of companies in the observability space is a testament to this. Restate has a lot of information about your application through the events in its log. You can now access and query all of that information through the UI.
The UI helps you answer complex questions, like "where in my chain of calls did my handler or workflow get stuck?", "how many times was this function retried and which step is failing with what error?", or "what function execution is blocking my invocation from getting executed?". Take a look and see for yourself.
The UI is bundled with Restate Server and accessible at the admin port http://localhost:9070.
Start building with Restate
Get started with the quickstart guide, star the GitHub project, and join the community on Discord or Slack. Be the first to know about new releases and technical posts — like the upcoming deep-dive on Restate’s architecture — by following us on X, LinkedIn, Bluesky, or subscribing to email updates.
Restate is also available as a fully managed service running in our cloud or yours. Try Restate Cloud for free and contact our team for more information.
Useful links
- Check out the full release notes for Restate
- Get started with Restate, or if you already know Restate, try running a cluster locally.
- Have a look at our previous blog post introducing Restate’ distributed architecture, or at the underpinning of Restate’s design that Every System is a Log