Distributed Restate - A first look
Stephan Ewen, Ahmed Farghal, Till Rohrmann
For a couple of months, we have been working hard on the distributed Restate server runtime, and today it is time to give you a first look at what you can expect. Teaser: A lot of good stuff!
For the impatient: you can skip right to the demo, where we show Restate running an order processor across multiple AWS regions, take down one region💥 and see everything continue and preserve consistency. If you want more context, read on…
Distributed deployments with Restate serve multiple purposes:
- Higher availability, by having another process ready to take over, rather than waiting on the failed process (or container/pod) to be rescheduled. As a special case, this involves deployments across multiple availability zones or even regions that tolerate outages of full zones and regions.
- Better durability, by persisting copies of the data across multiple zones / regions.
- Scalability, by spreading load over multiple nodes.
First of all, Restate’s distributed runtime is not a bolt-on that we started adding after the 1.0 release. The system has been designed from day one as a distributed system. The single-node version is already running multiple partitions across CPU cores, effectively using the same scale-out architecture that the distributed version will use. The control-plane/data-plane separation is already running in the single-node version.
To go fully distributed, we needed to finalize features like the replication of the durable log, snapshotting of RocksDB, switching of leaders, and distributing the table scans for the DataFusion SQL engine, etc.
Distributed Restate from 10,000 feet
Restate is a distributed architecture in a box (single binary), containing all the parts needed for a distributed durable invocation, execution, messaging, and orchestration engine. Restate needs only an ephemeral local disk and an object store for async snapshots.
Restate receives service invocations (calling durable functions, objects, or workflows) via HTTP calls or via events from Kafka. After running them through its internal machinery, Restate pushes the invocations (and contextual data like journals and state) to the service handlers, which may run as containers, FaaS, etc.
Restate scales through horizontal partitioning (similar to systems like Kafka), and invocations are attached to either a specific partition when required (derived from object key, workflow id, or idempotency key) or a randomly chosen partition.
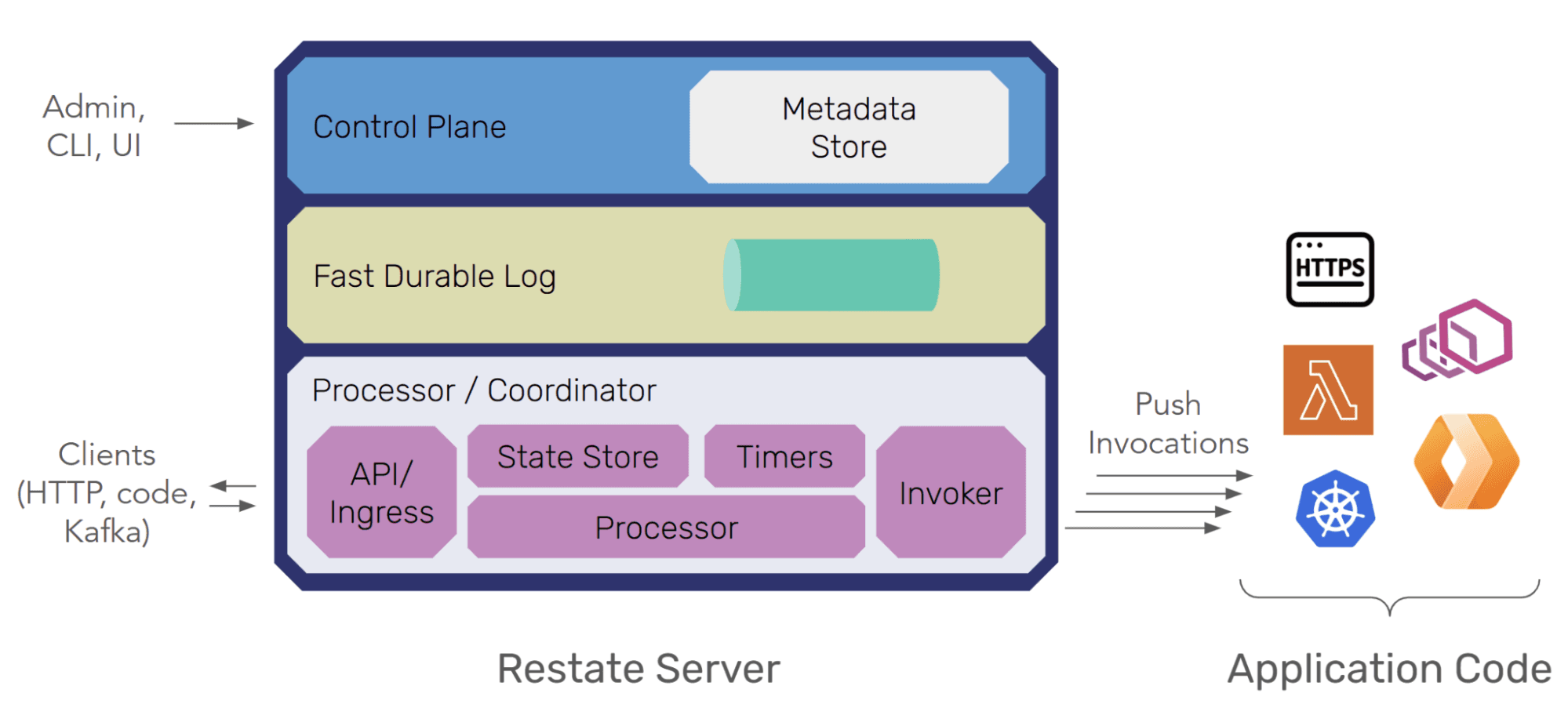
Control Plane and Data Plane
Restate’s layers include the processors (which run the invocation state machines and store all state and timers), the durable log (to which invocations, journal entries, state updates are written), both together forming the data plane. The third layer is the control plane (storing metadata about services and consensus, and coordinating failover). These three layers are typically present in distributed cloud services, often backed by different systems (queues, databases, locking services like etcd, …). And while one can separate these roles into different Restate processes, here we assume that they run within the same process.
One of the key elements of Restate’s design is that the log is the ground truth. The processor materializes state (Virtual Objects, journals, keys and cached results, etc.) into a local RocksDB instance running on ephemeral storage. But all that state is deterministically derived from the log, so as long as the log is safe, the data is safe. The RocksDB state is backed up periodically by snapshotting to S3 or a similar object store (to avoid costly re-building from a very long log history), but that is an asynchronous process, off the critical path.
Replication
To ensure durability for each operation, all appends to the log are synchronously replicated. Each log partition has a leader and a set of nodes to store copies of the events; a quorum of nodes needs to acknowledge each event. When the partition leader fails or becomes unresponsive, leadership transitions to a new node. The exact failover procedure is quite elaborate (because nodes need to agree on the exact point of handover) and we’ll dive into that in a follow-up article.
By default, the processors also run in a leader/follower-style, where both materialize the state changes indicated by the events from the log into RocksDB, but only the leader actually triggers invocations in services. Physically, each process runs a mix of leader and follower processors. Leader processors periodically snapshot the RocksDB state to an object store, to avoid long replays after failures. It is worth noting that running followers for the processors is a failover latency optimization we run by default.
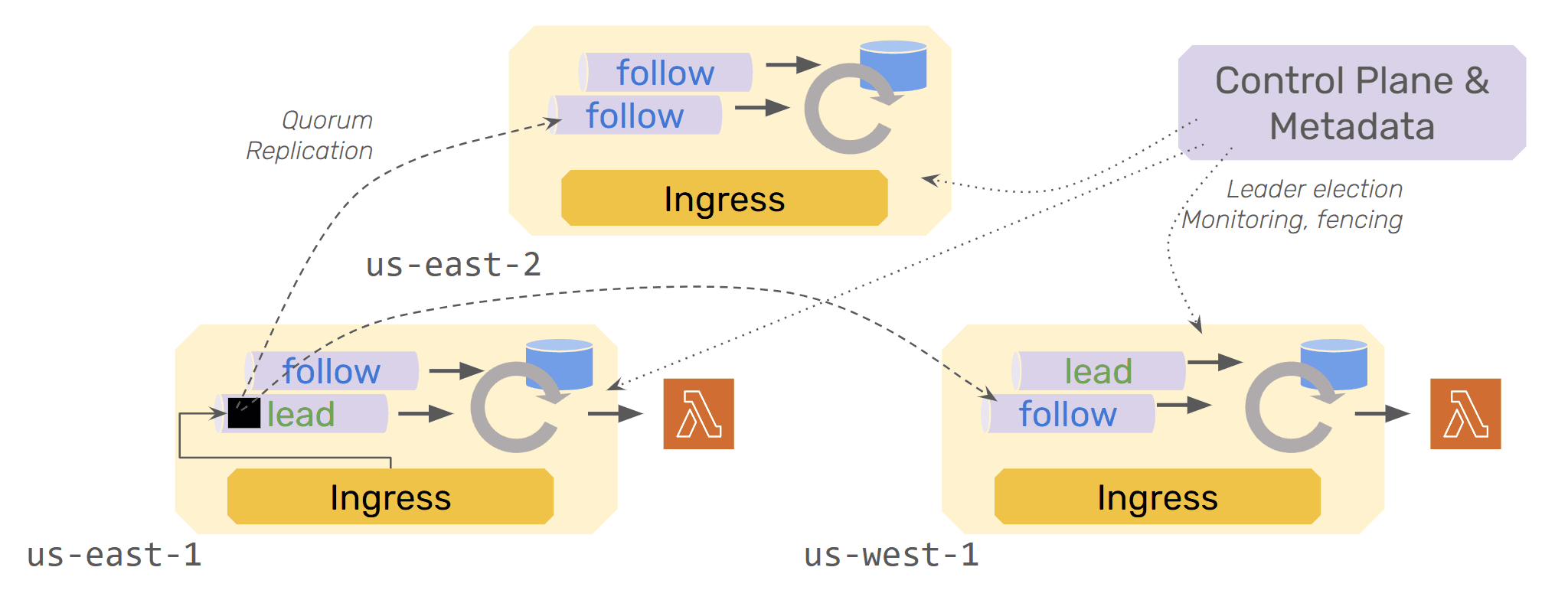
When an invocation is made to Restate, it enters the system at the ingress, which is Restate’s API gateway (and Kafka consumer). The ingress picks a partition for the invocation: If it is targeting a virtual object, specific workflow, or has an idempotency key attached, then those keys/ids determine the partition, and the event is sent to the leader for that partition. For other invocations, the ingress can pick any partition with a local leader.
There are many details missing in this description, which we will share in a follow-up. For the sake of this sneak peek, we want to focus on the high-level picture.
Demo
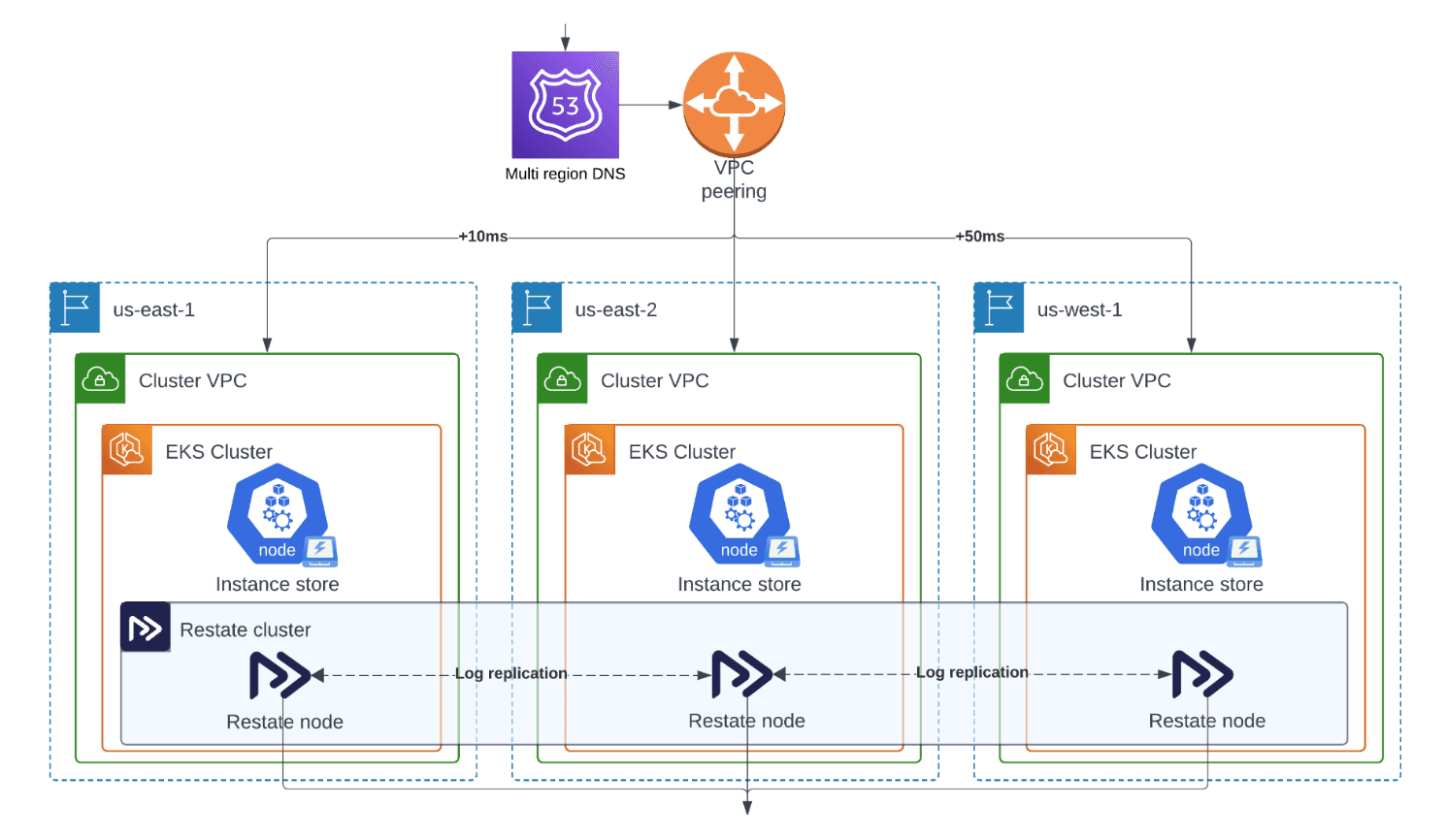
The best way to show what you can expect is through a demo. We picked a scenario that is particularly challenging - geo-distributed deployments, with nodes in different AWS regions.
The demo scenario is one that needs strong consistency [*]: Trading/Order Processing. The code for the demo can be found in this repository, which also contains a more detailed description of the scenario. Users create orders and add order items to the order. Adding an item places a temporary reservation in the quantity of the assets (an ‘earmark’). When done, users can close the order, which runs a workflow booking each individual order item. The workflow can fail if an individual item cannot be booked after a certain number of attempts, and will reverse all previous bookings in that case. The workflow follows the SAGA pattern for this. Orders can be canceled, which either removes earmarks or reverses already-executed orders.
The implementation contains two parts: First, the Order State Machine, which tracks the status, order items, and implements the transition logic between steps, like placing/removing earmarks. It is implemented as a virtual object in Restate. Second, the Order Booking Workflows (SAGA-style) for executing and reversing the orders.

The deployment is a three node cluster of Restate Server instances, across us-east-1, us-east-2, and us-west-1. Nodes push invocations to a service endpoint address that can be resolved in each region. Clients connect to different regions (sometimes alternate between connected regions) and make orders, add items, close or cancel randomly. At some point, we destroy all services in us-east-1 and watch everything continue smoothly.
Demo: Geo-distributed Restate order processor (YouTube)
Strong Consistency
If you watch the video, things seem to go pretty smoothly. Let’s discuss what are all the things that are NOT happening that would typically happen in many other setups (for example, if you were to build this on a Postgres/Aurora multi-region setup, which asynchronously replicates the data across regions).
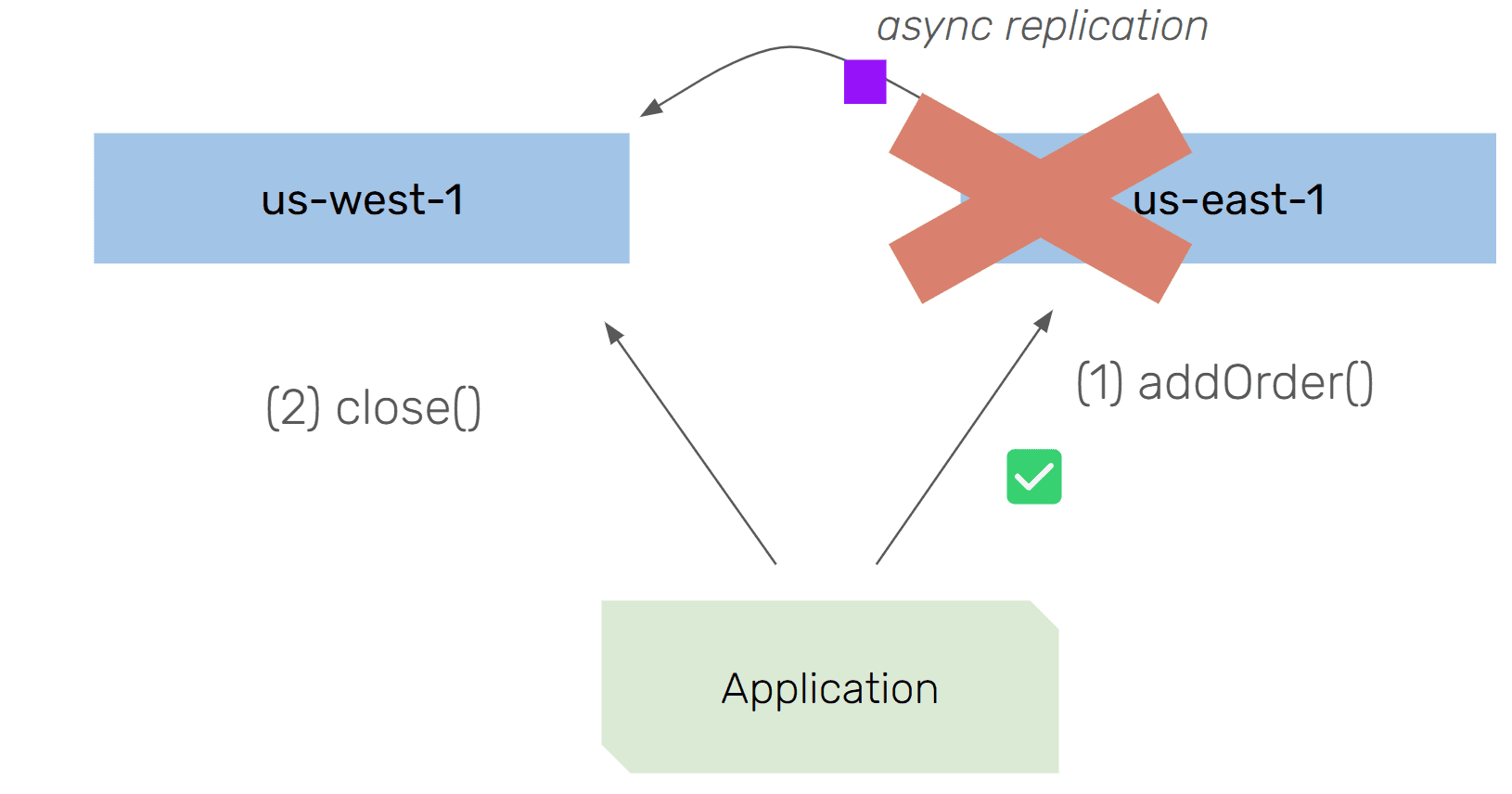
Lost or Duplicate Invocations
An order item that was added should never be lost. However, unless the system ensures durability across regions before ack-ing the order back to the client, the order may not actually be persistent (and thus lost) in case the region becomes unavailable before async replication was completed.
Concurrent Updates
If two clients are connected to different endpoints in different regions, and issue concurrent commands, the system needs to ensure strict ordering/queuing of commands across regions. Active/active storage systems with async replication (e.g., DynamoDB global tables) would overwrite each others’ entries and result in an undefined behavior.
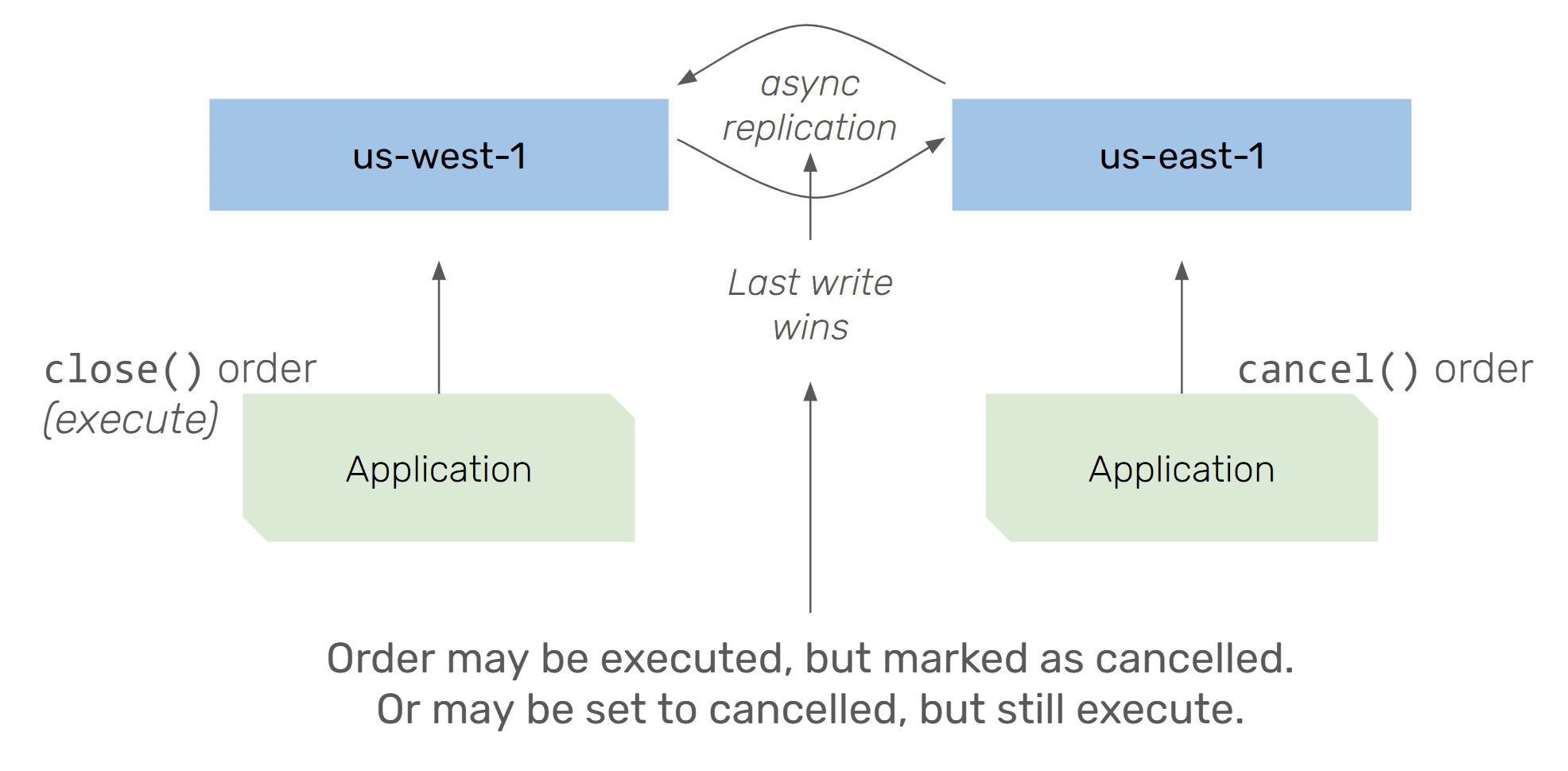
Lost Journal Entries / Broken SAGAs
Losing journal entries is a disaster for durable execution. Initially, one might think that the worst case here is re-executing a step, and if one models steps as idempotent anyways, it should not be a big deal. But the real danger is breaking the control flow between execution attempts.
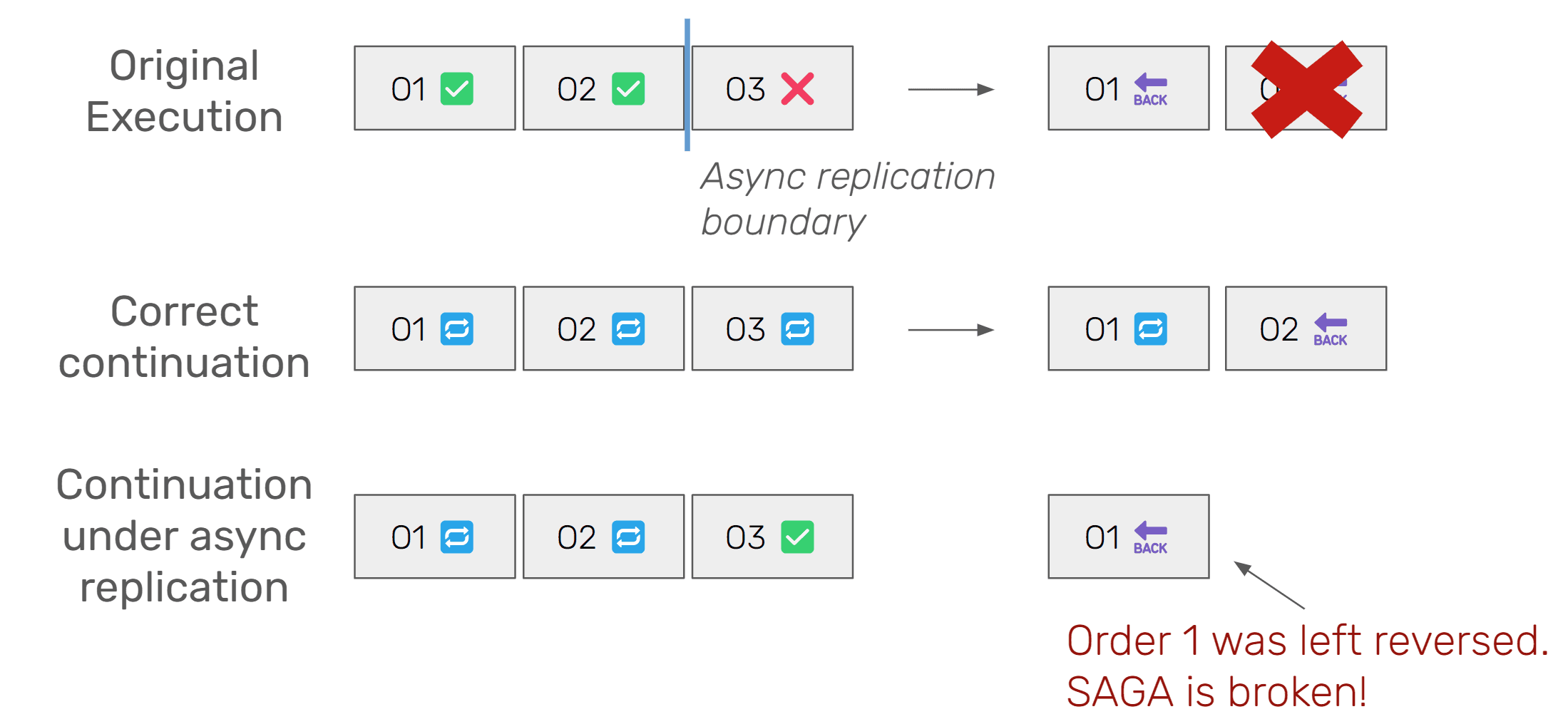
For example, consider an order booking SAGA for three order items: The first execution might successfully book two items, but then fail on the third (network error, exhausted retries), and the SAGA would enter the compensation code path. Any retry execution now needs to reliably enter the compensation code path, because some order items may have been undone already.
If the journal entry capturing the failure of the third item is lost, a retry-execution might actually succeed in the third item, and assume overall success, and result in a state where some items are booked and some have been reverted.
Durability of journal entries is absolutely paramount for such a system. Otherwise, all sorts of code and control flow might break. If your durable execution engine might lose journal entries under a relevant failure scenario, you are back to square one: you need to develop defensively. Losing a journal entry in a relevant failover scenario shouldn’t even be an option.
Why does this work so well in Restate?
It is worth pointing out that this setup is really challenging - running this application across multiple regions, tolerating region failures, and maintaining linearizable views on state and consistent ordering of all operations, with decent latencies.
There is a lot to unpack when it comes to Restate’s design and architecture, and this will need another blog post. But the high-level points are those:
-
Log-first architecture: This may be the most important point. Making an append log durable across regions and supporting good append latencies is a much simpler task than making a database work across regions. Databases have way more complex access patterns (not just appends to the txn log, but table page accesses, lock acquisitions, or ensuring txn timestamp ordering), making it harder to get good performance when latencies between nodes are high.
-
Latency-tolerant log implementation: Restate’s log tolerates higher latencies between regions better than some popular implementations, by using an approach with copy sets and write quorums, rather than for example Kafka’s in-sync-replica model, where only nodes with the full prefix of the log are able to participate.
-
No dependency on a database: Not relying on an external database helps in multiple ways:
(1) Restate does not inherit the database's limitations, like being available only in a single region, or doing async replication across regions, or requiring costly quorum reads that increase latency (for example in Cassandra clusters).
(2) There is no need to coordinate leadership and failover between the database, a queueing system, and the orchestrator or workflow server. When those are independent components, you need a way to co-locate database and server leaders in a region, move leaders between regions during failover, align and secure leader terms with leases and epochs everywhere, and generally deal with the fact that the database and the queue and the server all have their independent failover model and semantics that you need to align (hello rabbit hole of cornercases). Restate’s way of managing the log and processors together avoids all of that.
-
Tight integration between log and processor: The Restate-internal control plane co-locates partition leaders and processor leaders. Processors use the log for leader election - avoiding a lot of coordination by using the same component for storage and leader isolation.
-
Push model for invocations: Because invocations are pushed to services (rather than letting workers pull activities from queues) there is no need to coordinate failover with workers. Fewer pieces to coordinate means faster failover and fewer possible situations where things can go wrong.
Sometimes, it is worth building a system from first principles, rather than assembling a bunch of components around an existing database. It is very hard, but if you can pull it off, the benefits can be huge. Not only for performance and capabilities, but also because it is vastly easier to operate than a stack that combines separate distributed databases and workflow servers.
Timeline for the Release
We expect to release a first version of distributed Restate in January. Priority number one is ensuring correctness and reliability.
While some parts are incredibly hard to build (like the consensus log), many parts are also in some ways easier to build than most other systems. The architecture of Restate, specifically the processors, avoids distributed coordination in most places and has fewer individually moving parts and corner cases. The log is specialized towards having only the Processors as specific writers and readers, and sharing the same failover coordination with them.
Up next: Architecture in detail
In the coming weeks, we’ll kick off some articles detailing how Restate works and how it is able to achieve its properties.
For example, how does the log achieve consistency while maintaining low latencies, how does failover maintain correctness across all operations (log, invocations, state) and how does all of that play together to give you exactly-once state, durable RPC, and durable execution?
There are a ton of amazing designs, lessons, and research papers that influenced the architecture. We are excited to share more of these details with you.
Keep reading

Building a modern Durable Execution Engine from First Principles
The architecture of Restate, a Durable Execution engine built from the ground up.
Every System is a Log: Avoiding coordination in distributed applications
Distributed coordination makes application complex and brittle. Because all systems eventually build on logs, we can use a shared-log approach to eliminate most coordination. We discuss this conceptually and show how this is practically implemented in the open source project Restate.
Why we built Restate
Introducing Restate, a distributed application runtime that facilitates reliable communication, consistent state, scalability and failover.