From Prompt to Adventures : Creating games with LLMs and Restate's durable functions
[GUEST POST] Ivan Leo @ivanleomk
The code is open sourced at https://github.com/essencevc/cyoa
In this article, we’ll explore how to take a single user prompt and generate an entire Choose Your Own Adventure game from it using Restate.
On the surface, this seems simple - just a simple series of story branches for the user to navigate. But add image creation, audio synthesis and multiple LLM calls across a complex web of services and this quickly spirals out of control.
Traditionally, we might reach for a message queue for coordinating the requests between different services. Once we’ve done so, we would also need to code up a separate service to track any potential failures to handle the retries or requests that were dropped.
Restate simplifies this process significantly, helping us to build out and deploy complex workflows with confidence.
We’ll see how we can coordinate multiple services, track state updates and have automatic retries out of the box with their built in primitives.
What goes on behind the scenes
In our application, we allow users to describe a story that they have in mind in 1-2 sentences. For instance, given the prompt A Samurai finds himself in Tokyo in 2040 with nothing but a trusty sword in tow, we’ll generate an entire interactive story that a user can play.
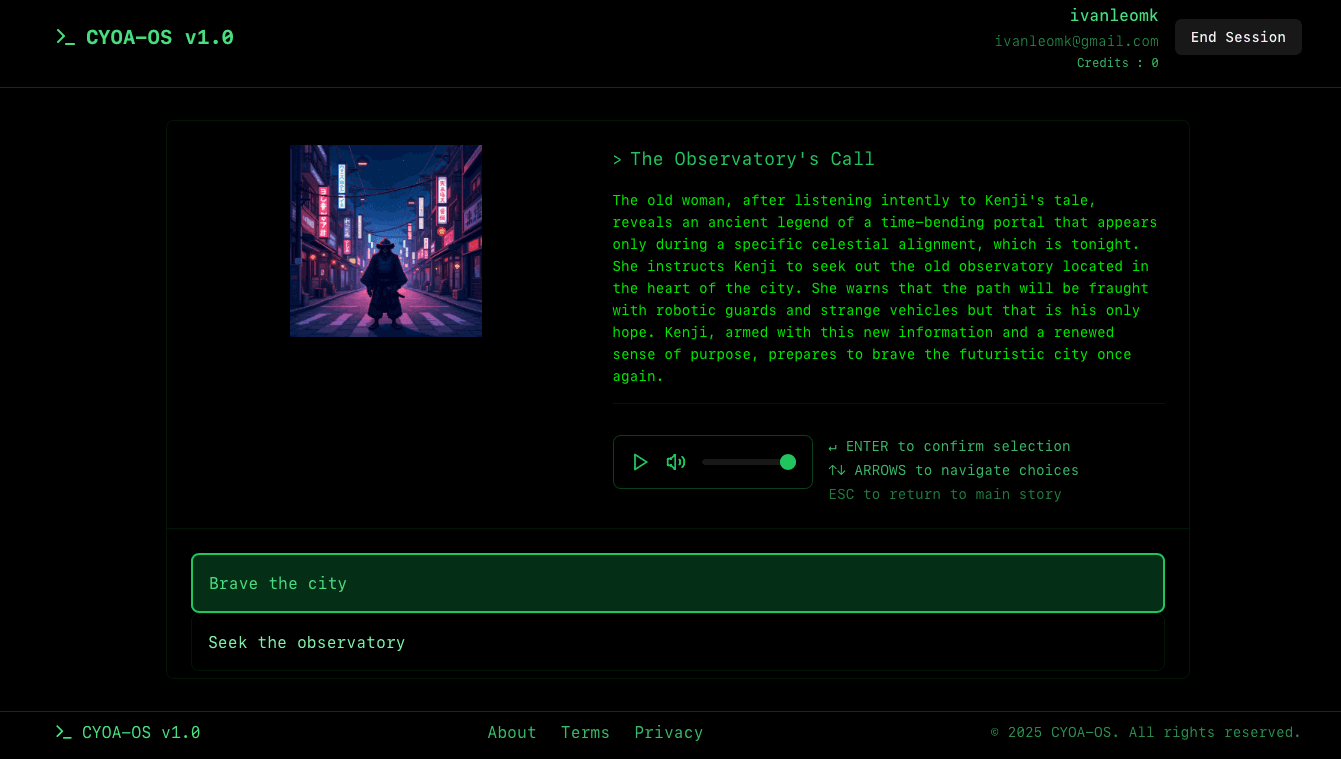
With each choice they make, the story advances in different ways. Depending on the choices they make, they end up in either good or bad outcomes. Behind the scenes however, this is a rather complex process as you’ll see below.
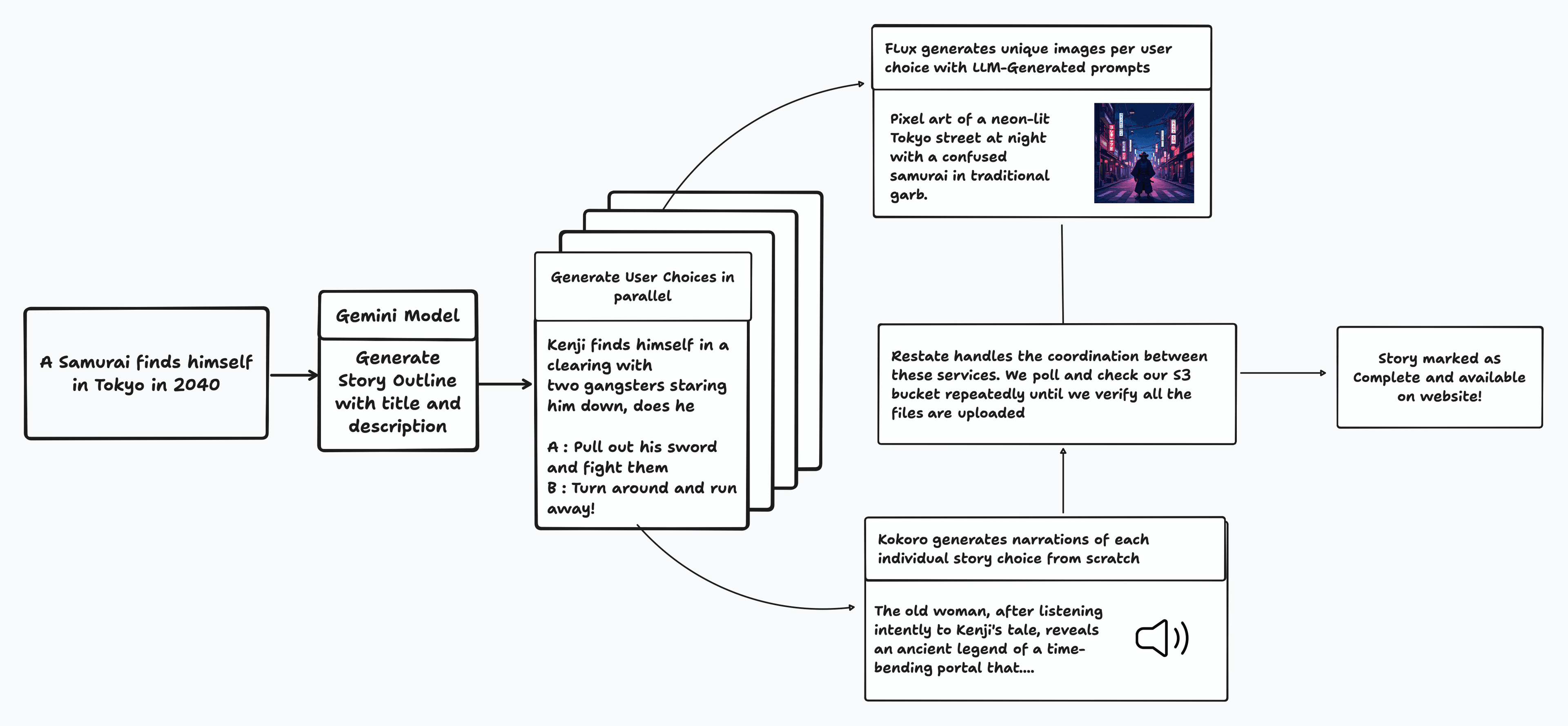
Once the user gives us a prompt, there are a few things that we need to do
- We need to generate a rich high level outline with character backstories, image prompts for a banner image
- Once we have this high level overview, we need a way to generate these choices iteratively in a quick and efficient manner
- We need to then take these image prompts and run them through flux to generate the actual images
- For each individual choice that the user can make, we need to generate an audio track using a Text-To-Speech (TTS) model
- On top of all of this, we need to make sure that the story is only marked as completed by verifying that all of the desired images and audio tracks have been generated
While these might sound straightforward, the real challenge lies in orchestrating the entire workflow. There were three main issues that we faced
- Extended Execution Times : Each images requires 15 seconds to generates, and this translates to about 7 minutes of execution time just for image generation. With every new choice that we allow the user to make, the amount of possible choices doubles, resulting in an exponential growth in the overall time needed to generate a story.
- Orchestration : Getting each individual service to work nicely and handling retries in case of failure is challenging, not to mention the expensive cost we’d incur for regenerating all of our stories, images and audio tracks from scratch
- Managing State Updates : In our case, we want to mark a story as completed only when we’ve finished generating the images and the audio. How do we track the state of these generation jobs in a simple manner.
Our image generation task alone takes about 15-20 seconds per story node. Multiply that across all the nodes that we’ve generated and we're well beyond the timeout limits of most serverless platforms. Add in audio generation, and we need a way to track dozens of parallel processes, handling failures and retries along the way.
Traditional approaches each come with significant drawbacks. With serverless functions, you're fighting timeout limits and need external databases to maintain state between invocations. Self-hosting brings its own challenges – you'll need message queues for job coordination, custom code for state management, and infrastructure for monitoring and scaling.
How Restate solves these problems
Restate streamlines the development of resilient applications by introducing durable handlers—functions that are guaranteed to run to completion, even in the presence of failures. This approach eliminates the need for custom retry logic; instead, you write standard functions that Restate makes durable by tracking their execution state in a central log.
These durable handlers are defined within Restate Services, which you can implement in any supported language, including Python, TypeScript, Go, and others. You can deploy them as either serverless functions or as a hosted server. The Restate Server acts as an orchestrator, coordinating all these services and managing their state.
By allowing you to focus on your business logic and allowing Restate to handle the rest, we get
- Automatic Retries and State Management: Restate maintains a journal to store the results of previous executions. In the event of an unexpected error, it can resume execution from the point of failure, regardless of whether you're using serverless functions or persistent servers.
- Ensured Execution of Requests: Each request is tracked by Restate using a unique identifier, ensuring it is executed without the need for an external message queue. Additionally, this identifier provides access to a key-value store unique to each request instance, simplifying the implementation of complex functionality.
- Built-in Concurrency Primitives: Restate offers useful concurrency primitives out of the box. For instance, you can implement polling logic using a
.sleep()method, handle unique webhooks with.awakeables(), and invoke different services registered with the same Restate server after a specified time using.object_send().
In our specific case, we wrote our entire service in Python, making it easy to iterate and experiment with our application logic and deployed the GPU intensive portions to Modal so that we could run them efficiently.

When the user submits a prompt, we validate that they have enough credits to do so and then submit a request to the Restate endpoint.
Our Restate endpoint then ensures our request is forwarded to our Restate service that generates our initial story description and choices for the user to choose from. Once we’ve generated an initial list of choices, we then fire off a set of requests concurrently to Modal to generate our audio narration and images.
Using the ctx.sleep method, Restate will suspend our function’s execution and then resume it 60 seconds later to see if we’ve finished uploading all of the individual files.
While we opted for this simpler approach, Restate also offers a ctx.awakeable method that will suspend execution until an external event resolves the awakeable, allowing the function to remain inactive without consuming resources and resume immediately upon task completion.
Code
Before walking through this portion, make sure that you’ve either configured a Restate cloud account and created a deployment or installed Restate locally.
You’ll need the cli installed so that you can debug and register your services easily with your Restate endpoint.
Let's examine how this architecture translates into code, focusing on three key implementation areas - configuring the Restate application, managing parallel story generation, and implementing reliable polling mechanisms.
Through these examples, you'll see how Restate's primitives handle complex orchestration tasks with minimal boilerplate code.
Configuring Your Restate Application
Getting started with your first Restate service is pretty straightforward since all you need to do is to define a restate.app and run it as a normal hypercorn server.
from restate import Workflow, WorkflowContext
from restate.exceptions import TerminalError
import restate
from pydantic import BaseModel
class StoryInput(BaseModel):
prompt: str
user_email: str
story_workflow = Workflow("cyoa")
@story_workflow.main()
async def run(ctx: WorkflowContext, req: StoryInput) -> str:
return "Success"
app = restate.app(
[story_workflow],
"bidi",
identity_keys=[
"public key goes here",
],
)Let’s highlight a few things here that make it easy
- Firstly, we can define custom validation for request bodies as we would normally similar to FastAPI using Pydantic Models
- Secondly, we can secure our endpoint using an identity key that we can check into source control to ensure that our Restate services only process requests from our Restate server
- Thirdly, we indicate to Restate that this is a persistent server that will use a bidirectional stream by using the
bidiparameter - Lastly, we can register our services by declaring them with a name - in this case we called our Workflow service
cyoaand then adding them as a list inrestate.app
Once we’ve defined this simple application in a file called main.py , we can run it with the command below
python -m hypercorn -c hypercorn-config.toml main:appWe can then register our new Restate service by running the command below
restate deployments register localhost:8000This notifies our Restate endpoint that we’ve deployed a new service called cyoa which we can verify by running the command
restate deployments list
DEPLOYMENT TYPE STATUS ACTIVE INVOCATIONS ID CREATED AT
http://192.168.1.1:8080 HTTP/2.0 Active 0 dp_17qUR1aioCQIDHo1lQyLf 2025-01-17T11:16:28.365
Now that we’ve configured our initial Restate service, let’s move on and see how we can generate our stories and choices in parallel.
Generating Story Choices
When building complex workflows, managing intermediate state can be challenging. With Restate, you can cache any intermediate computation results as long as they're JSON serializable. Restate provides built-in serializers for common types, but you can also create custom ones by implementing a deserialize and serialize method.
This is particularly valuable when we’re implementing complex recursive functions like our story generation, where we need to track multiple story branches and their relationships. This is an expensive bit of computation that we’d ideally like to only run once.
In our case, we’re returning a PydanticObject as the result of this generation that we then save by using the inbuilt PydanticJsonSerde method to cache the final result. This allows us to pick up right where we might have encountered an error, thus allowing us to write code that is more resilient without any cognitive overhead.
Let’s see how this works in practice.
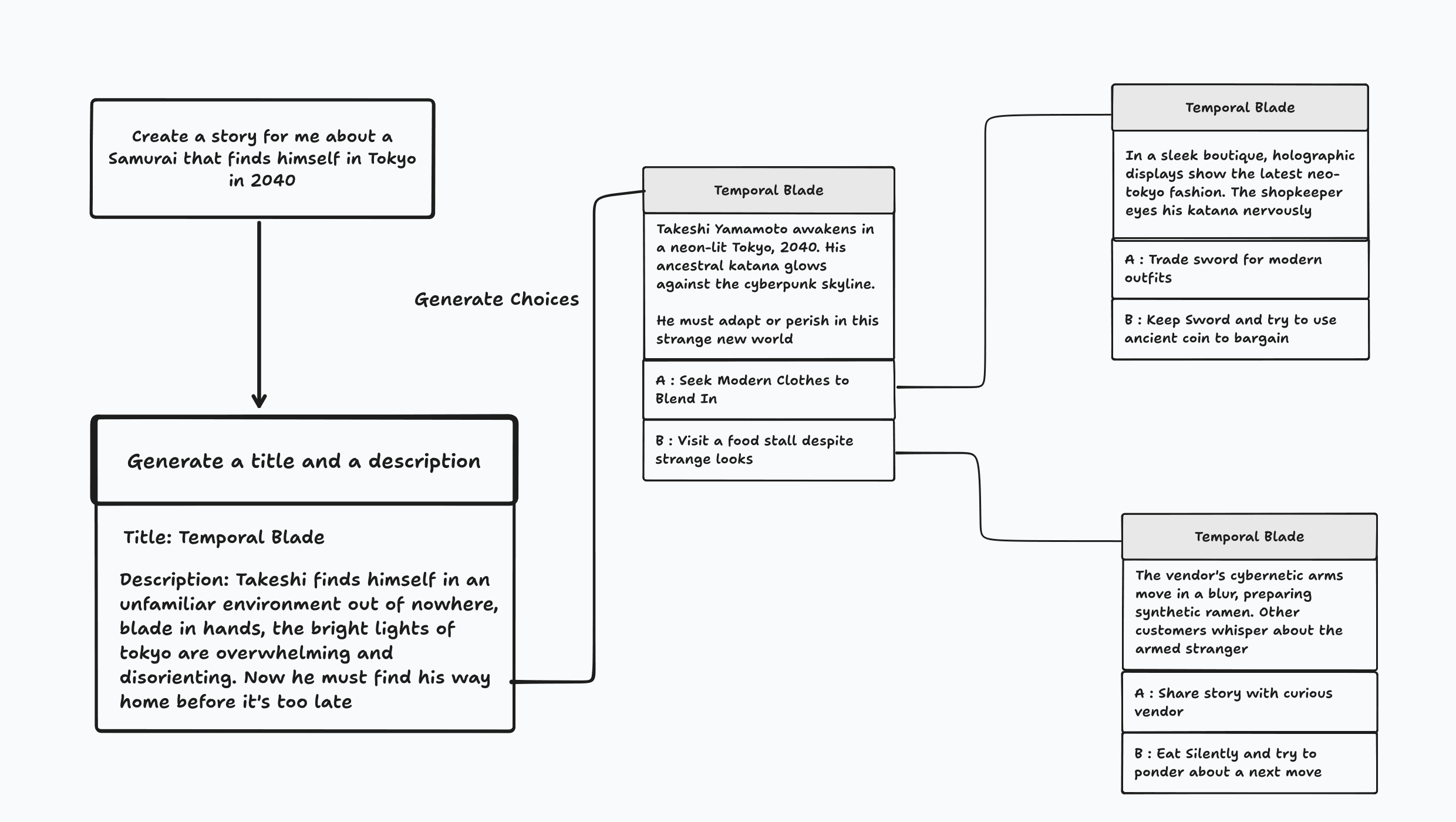
We do so in two steps
- First we take the initial user prompt and generate a descriptive story title and a description. We also generate a image prompt that we’ll pass to flux so that we can create a banner image
- Next, using this initial title and description, we then ask a language model, in this case
geminito advance the story to a moment where the user is faced with 2 mutually exclusive choices at the same time
We can use the instructor library here so that we can get reliable structured outputs from our language models used.
class StoryOutline(BaseModel):
title: str
description: str
melody: str
banner_image: str
def generate_story(prompt: str) -> str:
client = instructor.from_gemini(genai.GenerativeModel("gemini-2.0-flash-exp"))
return client.chat.completions.create(
response_model=StoryOutline,
messages=[
{
"role": "system",
"content": """
Here is a prompt provided by a user who wants to play an adventure game.
<prompt>
{{ prompt }}
</prompt>
Read the prompt carefully, identify specific details and elements and then generate the following
- A title for the story that's between 3-6 words
- A description for the story that's between 3-5 sentences. In this description, you must introduce the main character and set the scene. Make sure to mention the main character's name and what's at stake for them here in this existing situation implicitly.
- A short 1 sentence description for a banner image . This should be a description of a pixel art image that's suitable for the story as cover art. Be specific about the colors, style of the image, individual components of the image and the background.
""",
},
{"role": "user", "content": prompt},
],
)
Once we’ve done so, this gives us the initial outline for our story that we can use to generate our choices. Now, let’s implement a function that can generate choices for our story given an initial outline.
Since we want to generate choices that the user would be provided with if he followed a certain path, we need to provide the following context to our language model
- The initial story title and description
- The choices that were presented at each step prior to this current moment in the story and what the user would have hypothetically chose
- The outcome that was presented to the user once that choice was made
We can do so by writing a recursive function that will generate these choices that uses a max_depth parameter to ensure we keep the number of potential choices generated to a reasonable amount.
This is because for every additional choices that the user is allowed to make, the number of story nodes that we create doubles. For instance, just by allowing the user to make 4 choices, we have 32 story nodes, images and voice narrations to create.
from pydantic import BaseModel
class StoryNode(BaseModel):
title: str
story_description: str
banner_image_description: str
user_choices: list[str]
@field_validator("user_choices")
def validate_user_choices(cls, v, info: ValidationInfo):
context = info.context
if len(v) != 2 and context["remaining_turns"] > 0:
raise ValueError("Only provide two choices to the user")
if len(v) == 0 and context["remaining_turns"] != 0:
raise ValueError(
"You must provide two choices for the user to advance the story"
)
return v
class FinalStoryNode(BaseModel):
id: str
parent_id: str | None
title: str
description: str
image_description: str
choice_title: str
is_terminal: bool
async def generate_choices(
client, title, description, user_choices, max_depth,
semaphore, parent_id, choice_title
) -> list[FinalStoryNode]:
async with semaphore:
template = """
Based on the story title: {{ story_title }}
and description: {{ story_description }}
{% if previous_choices %}
Previous choices:
{% for choice in previous_choices %}
Choice: {{ choice.user_choice }}
Context: {{ choice.context }}
{% endfor %}
{% endif %}
Generate:
1. New chapter title and description (3-5 sentences)
2. Two choices for advancing the story (3-6 words each)
3. Banner image description (15 words, pixel art style)
"""
choices = await client.chat.completions.create(
response_model=StoryNode,
messages=[{"role": "system", "content": template}],
context={
"story_title": title,
"story_description": description,
"previous_choices": user_choices,
}
)
current_node = FinalStoryNode(
id=str(uuid.uuid4()),
parent_id=parent_id,
title=choices.title,
description=choices.story_description,
image_description=choices.banner_image_description,
is_terminal=len(user_choices) >= max_depth,
choice_title=choice_title,
)
if len(user_choices) >= max_depth:
return [current_node]
choice_nodes = await gather(*[
generate_choices(
client, title, description,
user_choices + [{
"user_choice": choice,
"options": " or ".join(choices.user_choices),
"context": choices.story_description,
}],
max_depth, semaphore, current_node.id, choice
)
for choice in choices.user_choices
])
return [current_node] + [node for nodes in choice_nodes for node in nodes]
We’ll then call this generate_choices method recursively using a wrapper function as seen below which returns a single StoryNodes object.
class StoryNodes(BaseModel):
nodes: list[FinalStoryNode]
async def generate_story_choices(story: StoryOutline) -> StoryNodes:
sem = Semaphore(50)
client = instructor.from_gemini(
genai.GenerativeModel("gemini-2.0-flash-exp"), use_async=True
)
final_nodes = await generate_choices(
client, story.title, story.description, [], 4, sem, None, "Our Story Begins"
)
return StoryNodes(nodes=final_nodes)
Caching the result of this function call is as simple as adding the following few lines to our current Restate application. Notice how we’re catching and throwing the TerminalError. This helps prevent an endless retry loop and tells Restate to only try this process once.
def wrap_async_call(coro_fn, *args, **kwargs):
async def wrapped():
start_time = time.time()
result = await coro_fn(*args, **kwargs)
end_time = time.time()
return result
return wrapped
@story_workflow.main()
async def run(ctx: WorkflowContext, req: StoryInput) -> str:
print(f"Recieved request: {req}")
db = DatabaseClient()
# This will take in a story prompt and then generate a story
try:
story: StoryOutline = await ctx.run(
"Generate Story",
lambda: generate_story(req.prompt),
serde=PydanticJsonSerde(StoryOutline),
)
except TerminalError as e:
print(e)
raise TerminalError("Failed to generate story")
try:
story_id = await ctx.run(
"Insert Story",
lambda: db.insert_story(story, req.user_email, req.prompt),
)
except Exception as e:
print(e)
raise TerminalError("Failed to insert story")
try:
choices: StoryNodes = await ctx.run(
"Generate Story Choices",
wrap_async_call(generate_story_choices, story),
serde=PydanticJsonSerde(StoryNodes),
)
except TerminalError as e:
print(e)
raise TerminalError("Failed to generate story choices")
Let’s take a quick step and see what we’ve implemented thus far
- We just created our first Restate service and registered it with our Restate endpoint so that we can forward requests to the service
- We’ve implemented two functions that can take in a user prompt and then generate entire story titles and descriptions along with a unique image prompt for each individual choice that the user can make
- Lastly, we’ve used Restate’s
ctx.runmethod so that in the event we run into errors, we can retry our function from where we last picked off, thus limiting any potential expensive retries in the event of an error. It’s important here to note that we get this same benefit irregardless of whether this was deployed as a serverless function or a persistent server.
With this in mind, let’s now move on to the next section, where we’ll implement two functions that will generate the images and audio narration for us.
Generating Images and Audio Narration
In our previous section, we implemented a function that generated a list of FinalStoryNode objects with the following definition.
In this section, we’ll do two things
- First we’ll implement two function to help generate an image and an audio narration for each story choice that we’ve created
- Then, we’ll write a loop to poll our
s3bucket until we’ve verified that we’ve generated a unique image and narration audio track for each story choice
We can see that from the FinalStoryNode definition, each of it has a description and a image_description attribute. We’ll be using two modal endpoints that we deployed previously to take these two attributes to generate the audio and image - you can find the code for the audio endpoint and the code for the image generation here.
class FinalStoryNode(BaseModel):
id: str
parent_id: str | None
title: str
description: str
image_description: str
choice_title: str
is_terminal: bool
Since Modal provides serverless GPUs, we can just fire off a request for each story node that we have and let Modal handle the rest. We can do so by using the asyncio.http library and throwing a timeout error 1 second in, this allows us to avoid waiting for the request to resolve.
We do this both for our image and audio generation requests, relying on Modal to manage the concurrent requests. To verify whether we’ve generated an audio file and image file for each story node that we’ve generated, we can poll our s3 bucket.
def get_story_items(story_id: str) -> list[str]:
"""
Get list of image filenames for a given story ID from S3 bucket
Args:
story_id: UUID of the story
Returns:
List of image filenames (without .png extension)
"""
try:
s3 = boto3.client(
"s3",
aws_access_key_id=Env().AWS_ACCESS_KEY_ID,
aws_secret_access_key=Env().AWS_SECRET_ACCESS_KEY,
region_name=Env().AWS_REGION,
)
response = s3.list_objects_v2(Bucket="restate-story", Prefix=f"{story_id}/")
if "Contents" not in response:
return {
"images": [],
"audio": [],
}
return {
"images": [
obj["Key"].replace(f"{story_id}/", "").replace(".png", "")
for obj in response["Contents"]
if obj["Key"].endswith(".png")
],
"audio": [
obj["Key"].replace(f"{story_id}/", "").replace(".wav", "")
for obj in response["Contents"]
if obj["Key"].endswith(".wav")
],
}
except ClientError as e:
print(f"Error accessing S3: {e}")
return []
Since the result of polling our s3 bucket is going to vary depending on how long has passed since we’ve fired off the requests, we’ll need to store the result of the query in a ctx.run call. This ensures that Restate can replay all of the previous invocations of get_story_items in the correct order and resume where it left off.
We can then ask our function to sleep for 60 seconds with the ctx.sleep method which will suspend this specific function invocation for 60 seconds.
while True:
# We poll our S3 bucket and wait to see if all the images are there.
images_and_audio = await ctx.run(
"Get Story Images", lambda: get_story_items(story_id)
)
remaining_images = expected_images - set(images_and_audio["images"])
remaining_audio = expected_audio - set(images_and_audio["audio"])
if len(remaining_images) == 0 and len(remaining_audio) == 0:
break
iterations += 1
print(
f"Iteration {iterations} : {len(remaining_images)} images and {len(remaining_audio)} audio remaining"
)
# We wait for at most 10 minutes. If the story is not ready, then we just give up.
if iterations > 10:
break
await ctx.sleep(delta=timedelta(seconds=60))
Once we've verified that the images and audio files have been generated, we can break out of this loop and mark the story as completed.
What's remarkable about Restate is that even if the entire process is interrupted during the sleep period—whether due to a system crash or intentional shutdown—Restate ensures the computation will resume seamlessly using its durable timers.
These timers are resilient to failures and restarts, allowing processes to pause for extended periods, even up to several months, and automatically resume upon recovery.
Conclusion
In this article, we saw how Restate enabled us to build complex long-running workflows with ease. By leveraging Restate's built-in primitives, we transformed what would typically require hundreds of lines of infrastructure code spread across multiple services into a cohesive implementation.
Whether managing extended execution times for image generation, coordinating multiple AI models, or implementing reliable polling mechanisms, Restate's approach significantly reduces the complexity of building robust and complex pipelines.
With Restate, adding new features or services becomes a matter of extending your business logic rather than managing additional infrastructure complexity. Whether you're building with Python, TypeScript, Go, Java, Kotlin, or Rust, Restate provides the tools needed to focus on what matters - creating compelling user experiences rather than wrestling with infrastructure.
Check it out today at restate.dev .
Keep reading

Resilient, observable agents with Restate and Arize Phoenix
Combine Restate and Arize Phoenix for agent reliability, observability, and evaluation in one stack.

Agent checkpointing is far from production-grade resiliency
Checkpointing helps with recovery, but agents are distributed applications and making them durable requires more than that.

Resilient, observable agents with Restate and Langfuse
Combine Restate and Langfuse for agent reliability, observability, and quality control in one stack.