Solving durable execution’s immutability problem
Jack Kleeman
In the last few years we’ve seen an explosion of durable execution tools and platforms. The general principle is this; computers are now so fast that they can write down the result of every non-trivial task to a persistent store. And by doing this, they have the ability to perfectly recover from transient failure by replaying the journal of tasks already completed, fast forwarding to the point where they failed and continuing like it never happened. With some care and attention, this can be achieved with minimal impact to the programming model or the performance characteristics, leading to an irresistible value proposition. Right?
Well, there are a few hard problems remaining. Probably the hardest problem in durable execution, as in many areas of infrastructure, is safe code updates.
Without durable execution, updating code is typically not such a big problem. Assuming some form of retries happen, a request might start on an old version of code, get evicted partway through, and then retry on the updated version of the code. In practice, this is not a problem if both handlers are idempotent (as they must be anyway for retries to be viable), and if they accept the same input parameters and have roughly compatible behaviour. You might end up with some aspects of the business logic of the old version, and some aspects of the new version, but most of the time you wouldn’t be too concerned about this.
In durable execution land, however, even fairly minor changes to a handler while a request is in-flight can cause the request to start failing, requiring human intervention. For example, if my handler is part of a checkout flow, I might want to add a step at the start that calls an external service to check if there’s a sale on. Intuitively, I would expect that in-flight requests that have already progressed past where the new step is inserted would be unaffected. But that’s not true! Any in-flight request that started on the old version of code and is replayed on the new version will fail, or perhaps even have undefined behaviour - because it will replay through the point where the discount check should have been made, find that it does not have anything in its journal for that, and will not know how to proceed. The journal no longer matches the code.
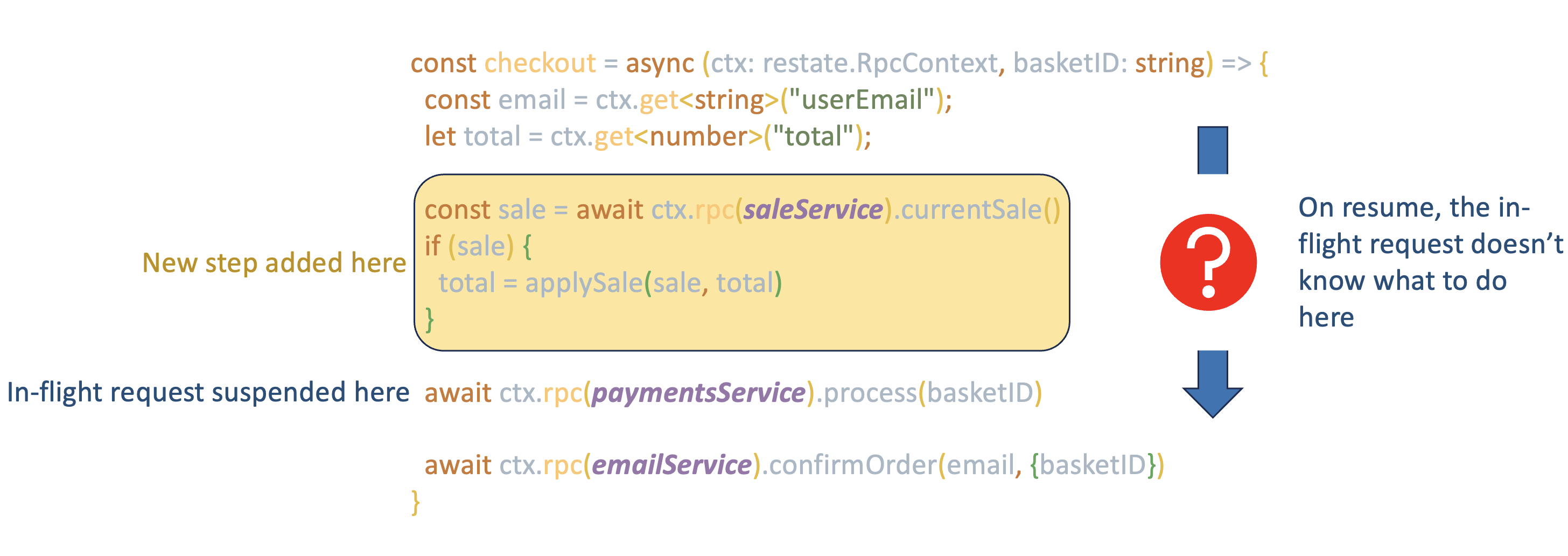
This is the immutability problem; the code executing a given request must never change in its behaviour, despite the potential for requests to be replayed long after they started.
The state of the art
Every durable execution platform has an approach to solve this problem. Let’s review a few of them:
Azure durable functions
Durable functions are effectively event consumers that are deployed to the Azure functions platform. They don’t usually execute each other, but instead apply durability to a set of methods within one deployed Azure function. The code is mutable, and replays will always execute over whatever is the latest version of that function.
Their recommended update strategy is to deploy the new version of the code alongside the old one, so that in-flight requests will not see an update. They propose two methods for this:
- Copy and paste changed methods of the overall workflow as new methods in the same artifact (they would say ‘functions’ inside a ‘function app’), and update callers to use the new methods for new requests. Those updates also require deploying new versions, however, so this needs to be done recursively until the call chain leads to the entry point, and so this isn’t recommended.
- Don’t update the existing deployment at all, but make a completely new deployment of the whole package of code, and update callers of the durable functions api to use the new deployment. In-flight calls will keep executing against the old code.
Azure have the right solution; the ability to ensure that in-flight requests stay on the version they first executed on is awesome. But its not quite a first class citizen; ideally we’d want new calls to a given durable function to automatically use the latest version. Needing to deploy a new durable function and update callers is cumbersome enough that in practice, people might just be tempted to ignore this problem for small changes and accept some failures.
Temporal
Temporal workers are event consumers deployed on reserved infrastructure, for example as containers in Kubernetes. As a result, the code is inherently mutable; you can just deploy a new container image.
Over the years there have been a few different recommended ways to handle versioning, but the current best-in-class solution is called worker versioning. In this model, a worker (which will likely include the code for many workflows) must be tagged with a build ID. When subscribing for work to do, a worker will only ask for replays that have already started on that build ID. One build ID is configured as the default, in which case it will also get new invocations that haven’t started anywhere.
For this system to work, a worker build needs to be kept running until any in-flight requests on it have completed. For short running workflows, that’s rarely an issue, although it still requires attention when removing old worker deployments - and you need to remove them eventually, because on reserved infrastructure they will cost you just for existing.
For long running workflows, however, this is not a solution. Replays can happen in principle months or years after execution started - this is one of Temporals most interesting capabilities. In these cases there are two problems with keeping old code around for so long. Firstly, the cost; if my requests run for a month and I do 5 breaking changes in that month, I need to run 5 workers concurrently. Secondly, there is a security and reliability concern about having arbitrarily old code running in your infrastructure - changes might not affect business logic, but will update database connection parameters, or update dependencies with security vulnerabilities; changes that perhaps do need to be applied to in-flight requests. So, there needs to be a cutoff point where we say that code is too old to run, and we might need to occasionally backport changes to older worker builds that are still running.
Where worker versioning is insufficient, Temporal offers a patch API; you can insert or remove steps by surrounding them in if statements, ensuring that new steps only run on new invocations and never on replay, or that removed steps still run on replay.
This is really flexible and great to get you out of a jam, but these patches accumulate in your code and need to be removed with extreme care.
AWS Step Functions
AWS Step Functions are described in JSON using a workflow language called ASL. While they may call out to code in the form of Lambdas, the durable execution only extends to steps within the workflow definition. And the definition is completely immutable - updates create a new version, which will be used for new workflow runs, but in-flight runs always use the version they first executed on. This completely solves the problem! Keeping around old versions costs nothing; it's just storing a single file, after all.
By the nature of Step Functions workflows, there are rarely security patches or infrastructure changes to worry about when keeping old versions around; all the ‘meat’ is in the Lambdas that the workflow calls, which aren’t subject to durable execution and so have no versioning problem beyond standard request/response type versioning.
Our approach
When building Restate we wanted to mix and match the best of all these approaches. Step Functions have by far the best user experience - you simply do not need to think about versioning, all thanks to immutable workflows, but you’re limited to writing workflows in ASL. We really admire the workflow-as-code experience of Azure and Temporal, but code is inherently mutable and this can lead to headaches. How can we combine the two?
Restate ‘workflows’ are much more like normal code than they are like workflows; they appear like RPC handlers. There are no event consumers; the runtime always makes outbound requests to your services, which can run as long-lived containers, or as Lambda functions. You just need to register an HTTP or Lambda endpoint with Restate, which will figure out what services run there, create a new version for those services, and start using that version for new requests.
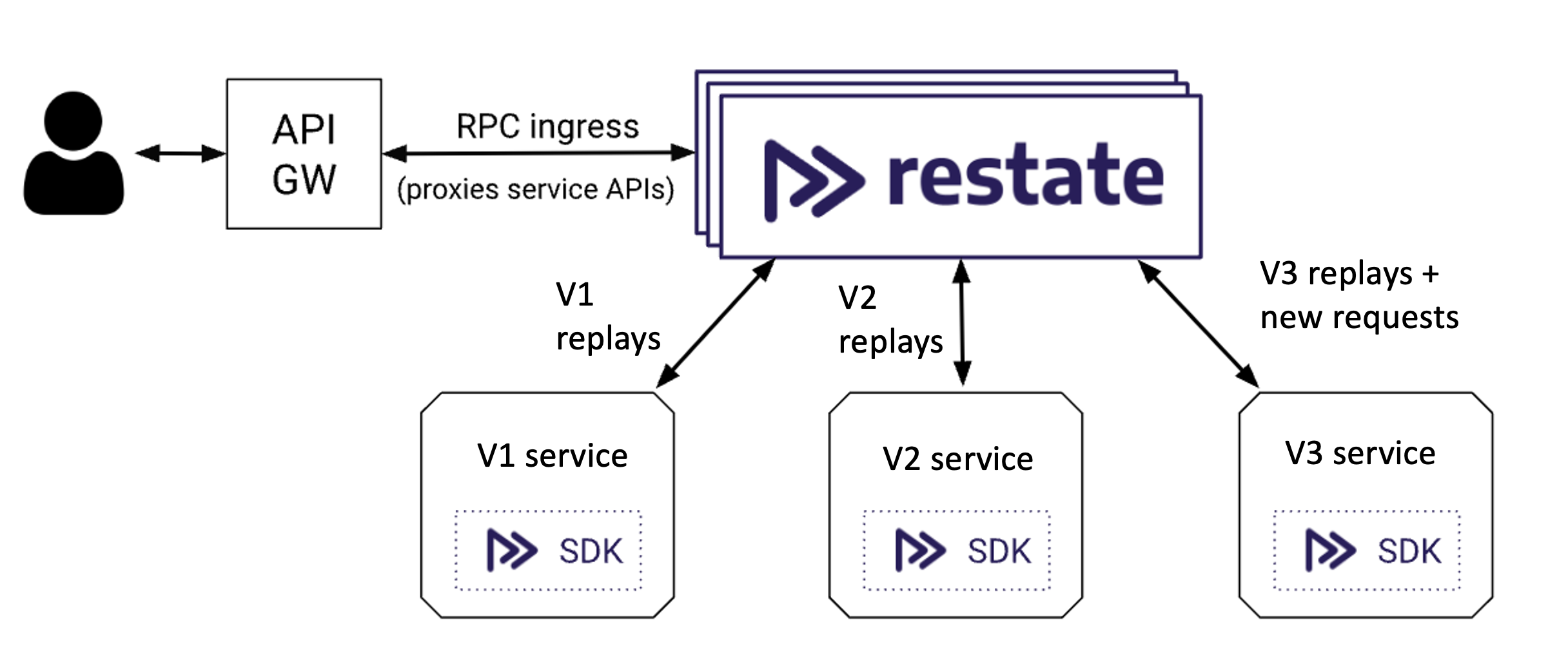
As a side effect of being able to run as Lambda functions, code immutability is easy! Published Lambda function versions are immutable - any update to code or configuration leads to a new version being deployed. Versions can be kept around indefinitely - and you can invoke old versions in exactly the same way as new ones, with no additional cost. By integrating our version abstraction with Lambda’s, we can offer the same experience as Step Functions; in-flight requests will always execute on the code they started with, and new requests will go to the latest code.
However, very long running handlers are still a headache. While Lambdas often have reasonably few dependencies beyond the AWS SDK, security patches could still be necessary, and infrastructure may change in such a way that old Lambda versions become non-functional. Furthermore, if we can bound our request durations to, say, an hour, then we have a tractable problem in other types of deployments, like containers in Kubernetes. We need to be able to keep old versions of code around for an hour. The easiest way to do this is to deploy both containers side by side in the same Kubernetes pod, serving on different ports or under different paths. In time, we hope to provide operators and CI tools that make this really easy to manage.
Writing handlers that take weeks to complete is still a hard problem, though. Perhaps we should be asking; why do people actually want to write code like that? Well, we’ll cover that topic in Part Two! And in the meantime, if you write code like that and want to tell us about it, join our Discord or Slack!
Keep reading

Agent checkpointing is far from production-grade resiliency
Checkpointing helps with recovery, but agents are distributed applications and making them durable requires more than that.

Updating AI Agents safely in production
How to safely update long-running AI agents with immutable deployments and pinned executions.

A remote control for your agents
Fine-grained control over in-flight and failed requests: cancel, pause, resume, restart.