What is Durable Execution?
Durable Execution is a programming paradigm that makes ordinary code resilient to crashes, restarts, and infrastructure failures. A durable execution engine records each step of a function as it runs, so when something fails, the function resumes from the last completed step instead of restarting from scratch, without losing state, repeating side effects, or requiring custom retry logic.
You may also see Durable Execution called workflows-as-code: it gives ordinary functions the reliability and recoverability that traditionally required a workflow orchestrator, a queue, a database for state, and a fair amount of glue code. The engine handles retries, idempotency, state persistence, and recovery; you write business logic in your favorite language using normal control flow.
Why is Durable Execution important?
Writing resilient applications is hard. Often, it involves many components interacting with each other: services, databases, message queues, workflows, etc. Infrastructure and process failures can happen at any point throughout the code execution. For more complex applications, it’s a near impossible task to test and handle all the permutations of how multistep code and services can fail.
Imagine this pseudocode function that processes orders
process_order() {
do_payment()
write_order_to_db()
send_confirmation_email()
}Now imagine all the ways in which this can go wrong. There could be a network glitch right after we triggered the payment, and we would need to make sure that we don’t charge our customer twice. Or what if you process the payment successfully but the database is down, and you can’t write the order to it? Or how do we know, during recovery, which steps got already executed? And this is just one function… Usually there are multiple services interacting with each other. This opens up an entire new box of potential issues: race conditions where multiple requests try to reserve the same product, or being able to add another product to your cart during the checkout process and buy it without paying for it, or issues like cascade failures and timeouts.
Teams typically address this by stitching together infrastructure: a workflow orchestrator for retries, a message queue for reliable async delivery, a key-value store for in-flight state, a scheduler for delayed tasks. The business logic ends up wrapped in custom retry, recovery, and coordination code, and engineers still spend hours chasing edge cases that escape testing.
Durable Execution collapses that stack. The engine takes responsibility for "what happened so far" and "what should happen next." Your code stays linear and readable, and failures stop being a design concern in every function you write.
How does Durable Execution work?
A durable execution engine works by journaling progress as code runs. Every meaningful step (an external API call, a database write, a sleep, a message sent to another service) is recorded to a persistent log before its result is returned to the function. If the process crashes, the engine restarts the function and replays the journal: each previously-completed step returns its recorded result instantly, until execution catches up to the point of failure and continues from there.
The result is code that looks ordinary but is automatically retried, recovered, and de-duplicated.
Restate implements this model with a log managed by the Restate Server, which acts as a proxy in front of your services. Services run wherever you run them today (Kubernetes, AWS Lambda, ECS, bare metal) and use a lightweight SDK to talk to the server. Here is a visual representation:

The core principles of Durable Execution
Across Restate, Temporal, AWS Step Functions, and similar systems, four principles consistently define the model:
- Journaled steps. Every external interaction is recorded to a persistent log before its result is observed by the application. The log is the source of truth for what happened.
- Automatic retries with idempotency. Failed steps are retried by the engine. Already-completed steps are not re-executed; their recorded results are replayed instead, making actions like generating an idempotency key to call an API trivial.
- Durable timers and signals. Sleeps, scheduled work, and inter-service signals (like awaiting a webhook or human approval) survive crashes and process restarts. A workflow can wait days or weeks without holding a process open.
- Resumability. Any in-flight execution can be recovered by any healthy worker. Recovery is transparent to the application code; there is no checkpoint logic to write.
These four properties are what separate a durable execution engine from "a queue with retries" or "a workflow YAML interpreter": the engine binds them together and presents them through plain code.
Durable Execution vs. workflow orchestration vs. event-driven
The distinction between these terms is not always clear. Here are the most important differences:
| Trait | Durable Execution | Traditional workflow orchestration | Event-driven / message queues |
|---|---|---|---|
| Workflow definition | Plain code in a general-purpose language | DSL, YAML, or visual graph | Implicit, emerges from message routing |
| State | Managed by the engine, transparent to the code | Managed by the orchestrator | Application's responsibility |
| Retries & idempotency | Built in, per step | Built in, per task | Per-consumer, manual |
| Long-running waits | Native (durable timers, signals) | Native | Awkward (timers, dead-letter queues) |
| Control flow | Anything the language supports | Limited to what the DSL exposes | Anything, but you wire it yourself |
| Best for | Business logic that needs reliability without giving up code expressiveness | Static, well-bounded processes designed by non-engineers | High-throughput, loosely-coupled streaming pipelines |
Workflow orchestrators like Airflow or classic BPMN engines work well for DAG-like business processes that are not latency-sensitive. Event-driven systems excel at decoupling services and absorbing load. Durable Execution sits in the middle: it gives engineers the expressiveness of code with the reliability guarantees of a workflow engine, and is increasingly the right default for transactional business logic and AI agents.
When to use Durable Execution
Durable Execution is a useful primitive whenever a function or process must complete reliably across failures, retries, or long waits. The most common applications:
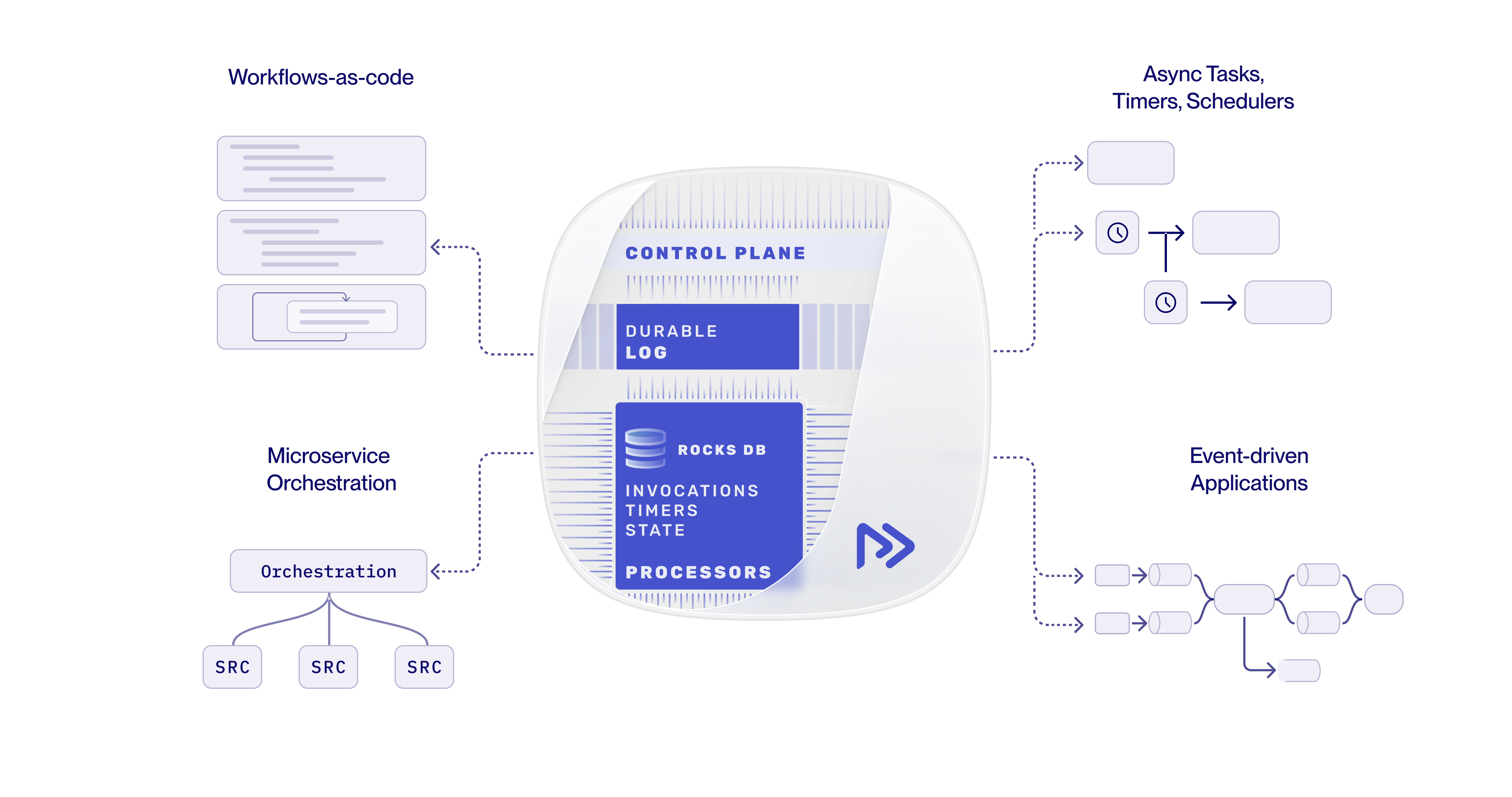
- Durable workflows: multi-step business processes (onboarding, provisioning, refunds, approvals) that span services and may take seconds or weeks.
- Microservice orchestration: coordinating calls between services with consistency, retries, and idempotency guarantees, without bolting on a queue and a state store for each interaction.
- Async tasks / background jobs: durable scheduling of work for now or for the future, including fan-out/fan-in patterns, durable webhooks, and re-attaching to running tasks.
- Event processing: exactly-once handling of Kafka or other stream events, where each event triggers transactional steps with full control flow rather than a static DAG.
- AI agents and LLM workflows: multi-tool agent loops where each model call, tool invocation, and human-in-the-loop step needs to be durable so a flaky LLM, a tool timeout, or a 24-hour approval wait does not lose progress or repeat side effects.
A Durable Execution code example
Here is a handler that processes an order: it charges the customer, reserves each item in inventory, and records the finalized order. Every external call is wrapped in ctx.run(...) so the engine can journal it. If the process crashes halfway through reserving items, the handler resumes from the next un-reserved item rather than re-charging the customer or starting over.
async function processOrder(ctx, order) {
const { customerId, items, totalAmount } = order;
// charge the customer (external payment service)
const paymentId = await ctx.run(() => chargePayment(customerId, totalAmount));
// reserve each item in inventory; each step is journaled
for (const item of items) {
await ctx.run(() => reserveInventory(item.sku, item.quantity));
}
await ctx.run(() => recordOrder(customerId, items, paymentId));
}The code reads like ordinary application logic, but is fully resilient to crashes, network glitches, and infrastructure failures. Restate journals every ctx.run(...) call, replays completed steps on recovery, and retries failed ones automatically.
Beyond execution: durable communication and state
At Restate, we believe Durable Execution is one of the building blocks of the applications of the future, but reliably executing a single function is just the start. Restate extends durability to two adjacent dimensions:
- Durable communication: request-response, async messages, webhooks, and delayed calls between services all flow through Restate, so a message in flight survives a crash on either end.
- Durable state and concurrency control: Restate's virtual objects keep per-key application state consistent and serialize concurrent modifications, so you no longer need a separate lock service or transactional outbox.
Together, these give you durability across execution, communication, and state: the three dimensions where distributed applications break.
Getting started with Restate
Restate is an open-source Durable Execution engine with SDKs for TypeScript, Python, Java/Kotlin, Go, and Rust. It runs as a single binary, on Kubernetes, or as Restate Cloud.
The fastest way in is the quickstart, which gets a durable handler running in your language of choice in under five minutes.
Frequently asked questions
What is Durable Execution in plain English? A way to write ordinary functions that automatically survive crashes, restarts, and infrastructure failures. The engine remembers what each function has already done and resumes from the right place after any failure, without re-running completed steps or losing state.
How is Durable Execution different from a workflow engine? Traditional workflow engines require you to express your process in a DSL, YAML, or visual graph and run it inside the orchestrator. Durable Execution lets you write the same logic in a general-purpose programming language, with full control flow, while still getting the reliability guarantees a workflow engine provides.
Does Durable Execution replace message queues? For many use cases, yes. Queues are often used to provide retries, scheduling, and async hand-off, all of which a durable execution engine offers natively. Queues remain the right tool to decouple producers from consumers.
Is Durable Execution slow? There is a small overhead from persisting results in a log, but resiliency is also usually not an opt-in, so if you don't use Durable Execution, you will still be wiring up a queue and a state store for each interaction, and paying at least the same overhead. Restate is optimized for low-latency Durable Execution via a highly-optimized log implementation, and lets you use Durable Execution anywhere in your application. A 10-step workflow has a p99 latency lower than 100ms. Learn more about Restate's architecture here.
Can Durable Execution handle long-running processes? Yes. A durable handler can sleep, await a webhook, or wait for human approval for weeks or months without keeping a process running. The engine persists timers and signals, and resumes the handler when the wait completes.